Pandas Indexing Examples: Accessing and Setting Values on DataFrames
Last updated:- loc example
- loc example, string index
- iloc example
- loc vs iloc
- Set value to cell
- Use column as index
- Set values according to criteria
- Fix SettingWithCopyWarning
Pandas version 1.X used throughout
View all examples on this notebook
loc example
Use .loc[label_values] to select rows based on their labels.
import pandas as pd
df = pd.DataFrame({
'name':['john','mary','peter','nancy','gary'],
'age':[22,33,27,22,31],
'state':['AK','DC','CA','CA','NY']
})
# select row whose label is 0
df.loc[[0]]
# select rows whose labels are 2 and 3
df.loc[[2,3]]
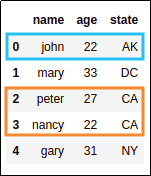 Source dataframe
Source dataframe
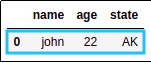 select row whose index label is 0
select row whose index label is 0
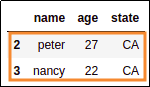 select rows whose index labels are 2 and 3
select rows whose index labels are 2 and 3
loc example, string index
Use .loc[<label_values>] to select rows based on their string labels:
import pandas as pd
# this dataframe uses a custom array as index
df = pd.DataFrame(
index=['john','mary','peter','nancy','gary'],
data={
'age':[22,33,27,22,31],
'state':['AK','DC','CA','CA','NY']
}
)
# select row whose label is 'peter'
df.loc[['peter']]
 Source dataframe
Source dataframe
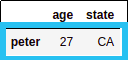 selected row whose index label is 'peter'
selected row whose index label is 'peter'
iloc example
Use iloc[<element_positions>] to select elements at the given positions (list of ints), no matter what the index is like:
import pandas as pd
df = pd.DataFrame({
'name':['john','mary','peter','nancy','gary'],
'age':[22,33,27,22,31],
'state':['AK','DC','CA','CA','NY']
})
# select row at position 0
df.iloc[[0]]
# select rows at positions 2 through 4
df.iloc[[2,3,4]]
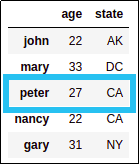
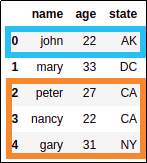 Source dataframe with integer index
Source dataframe with integer index
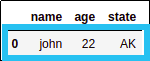 selected row at position 0
selected row at position 0
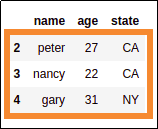 selected rows at positions 2 through 4
selected rows at positions 2 through 4
Naturally, iloc also works even if you have a string index:
import pandas as pd
# this dataframe uses a custom array as index
df = pd.DataFrame(
index=['john','mary','peter','nancy','gary'],
data={
'age':[22,33,27,22,31],
'state':['AK','DC','CA','CA','NY']
}
)
# select row at position 0
df.iloc[[0]]
# select rows at positions 2 through 4
df.iloc[[2,3,4]]
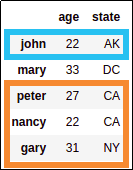 Source dataframe with string index
Source dataframe with string index
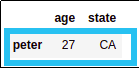 selected row at position 0
selected row at position 0
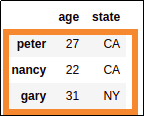 selected rows at positions 2 through 4
selected rows at positions 2 through 4
loc vs iloc
locandilocbehave the same whenever your dataframe has an integer index starting at 0
| loc | iloc |
|---|---|
| Select by element label | Select by element position |
| Can be used for setting individual values to cells | Cannot be used for setting individual values to cells |
Set value to cell
I.e. assign a value to an individual cell coordinate in a dataframe.
Use df.loc(<index-value>, <column-name>) = <new-value>
import pandas as pd
df = pd.DataFrame({
'name':['john','mary','peter','nancy','gary'],
'age':[22,33,27,22,31],
'state':['AK','DC','CA','CA','NY']
})
# set individual value
df.loc[0,'name'] = 'bartholomew'
# set individual value once more
df.loc[3, 'age'] = 39
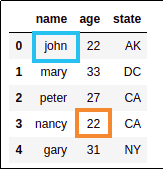 BEFORE: Source dataframe with
BEFORE: Source dataframe with original values
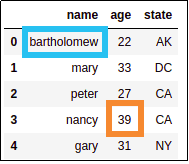 AFTER: changed john's name
AFTER: changed john's name to bartholomew and changed
nancy's age to 39
Use column as index
You should really use
verify_integrity=Truebecause pandas won't warn you if the column in non-unique, which can cause really weird behaviour
To set an existing column as index, use set_index(<colname>, verify_integrity=True):
import pandas as pd
df = pd.DataFrame({
'name':['john','mary','peter','nancy','gary'],
'age':[22,33,27,22,31],
'state':['AK','DC','CA','CA','NY']
})
df.set_index('name', verify_integrity=True)
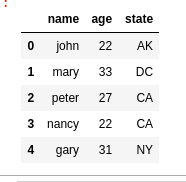 BEFORE: using default
BEFORE: using default numerical index
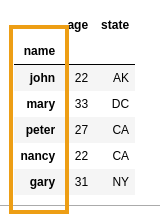 AFTER: column
AFTER: column name can only be used as index because it's unique
Set values according to criteria
To set multiple cell values matching some criteria, use df.loc[<row-index>,<colname>] = "some-value":
Example: You want to set lives_in_cali to True in all rows whose state is "CA":
import pandas as pd
# someone recorded wrong values in `lives_in_ca` column
df = pd.DataFrame({
'name':['john','mary','peter','nancy','gary'],
'age':[22,33,27,22,31],
'state':['AK','DC','CA','CA','NY'],
'lives_in_ca': [False,False,False,False,False]
})
# get the indices for the rows you want to change
index_to_change = df[df['state']=='CA'].index
# now use df.loc to set values only to those rows
df.loc[index_to_change,'lives_in_cali'] = True
 BEFORE: Someone recorded wrong
BEFORE: Someone recorded wrong values in column
lives_in_ca
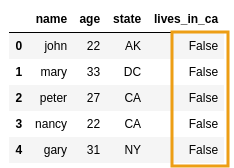
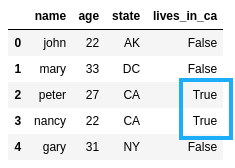 AFTER: fixed the column by
AFTER: fixed the column by setting it to
True in applicable rows
Fix SettingWithCopyWarning
 Annoying, right?
Annoying, right?
SettingWithCopyWarning happens when you try to assign data to a dataframe that was derived from another dataframe.
One quick way to fix it is to create a copy of the source dataframe before operating.
For example: from a source dataframe, selecting only people older than 30:
import pandas as pd
# source dataframe
df = pd.DataFrame({
'name':['john','mary','peter','nancy','gary'],
'age':[22,33,27,22,31],
'state':['AK','DC','CA','CA','NY']
})
BAD (operating on the source dataframe directly)
# create a derived dataset for people over 30 years of age df_over_30_years = df[df['age']>30] # and add a column df_over_30_years['new_column'] = 'some_value' #>>> SettingWithCopyWarning: #>>> A value is trying to be set on a copy of a slice from a DataFrame. #>>> Try using .loc[row_indexer,col_indexer] = value insteadGOOD: (call
copy()on the source dataframe first, and then add a new column)# by using .copy(), you're not operating on the source dataframe anymore! df_over_30_years = df.copy()[df['age']>30] # no error now df_over_30_years['new_column'] = 'some_value'