Apache Zeppelin, Spark Streaming and Amazon Kinesis: Simple Guide and Examples
Last updated:Zeppelin is a web UI for data processing tools. It can be used with spark and spark streaming (one possible source of data is Kinesis (also Kafka, Flume, etc)).
EMR supports Spark 1.6.0 and now it supports Zeppelin too.
Prerequisites
You need to add the Kinesis Jar as a dependency in Spark.
One way to do it is to change the last line in file /usr/lib/zeppelin/conf/zeppelin-env.sh so that it looks like this:
export SPARK_SUBMIT_OPTIONS="$SPARK_SUBMIT_OPTIONS --packages org.apache.spark:spark-streaming-kinesis-asl_2.10:1.6.0"
General Workflow
Suggested workflow for debugging Spark Streaming applications:
Write your code paragraphs and run them
Run
ssc.start()Wait a couple of seconds (at least as long as your
batchDuration)Run
ssc.stop(stopSparkContext=false, stopGracefully=true)Wait until output is printed onto the screen
Delete the checkpoints on DynamoDB
Go to step 1.
Troubleshooting common mistakes
org.apache.spark.SparkException: Task not serializable
If running code outside of any block, use @transient to prevent things from being "sucked" into the context, because then Spark will need to serialize it.
For example:
@transient val ssc = new StreamingContext(sc,windowDuration)
ssc.remember(rememberDuration)
@transient val streams = (0 until 1).map { i =>
KinesisUtils.createStream(ssc, appName, streamName, endpointUrl, regionName,
InitialPositionInStream.LATEST, windowDuration, StorageLevel.MEMORY_ONLY)
}
streams.print()
ssc.start()
Nothing gets printed after you stop the context
There are a couple of possible reasons for this:
Kinesis uses a DynamoDB instance to save checkpoints so that it can know what data it needs to read. You should probably delete the entries in the DynamoDB table used by Kinesis in between ssc.start/ssc.stop cycles.
You didn't call
print()on any streams.You stopped the context before the first batch window closed.
Adding external Jar Dependencies to Zeppelin
If, for some reason, calling z.load("org.apache.spark:spark-streaming-kinesis-asl_2.10:1.6.0") doesn't work for you (I sometimes see this error when I try to use the context after calling load()), you can SSH into your instance and edit the file at /usr/lib/zeppelin/conf/zeppelin-env.sh and change the last line so that it looks like this:
export SPARK_SUBMIT_OPTIONS="$SPARK_SUBMIT_OPTIONS --packages org.apache.spark:spark-streaming-kinesis-asl_2.10:1.6.0"
java.lang.IllegalStateException: RpcEnv has been stopped
You have probably stopped the underlying SparkContext as well as the StreamingContext. You need to restart the SparkInterpreter.
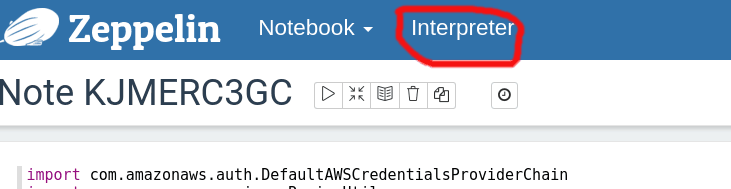 Click on "Interperter" to open the interpreter view
Click on "Interperter" to open the interpreter view
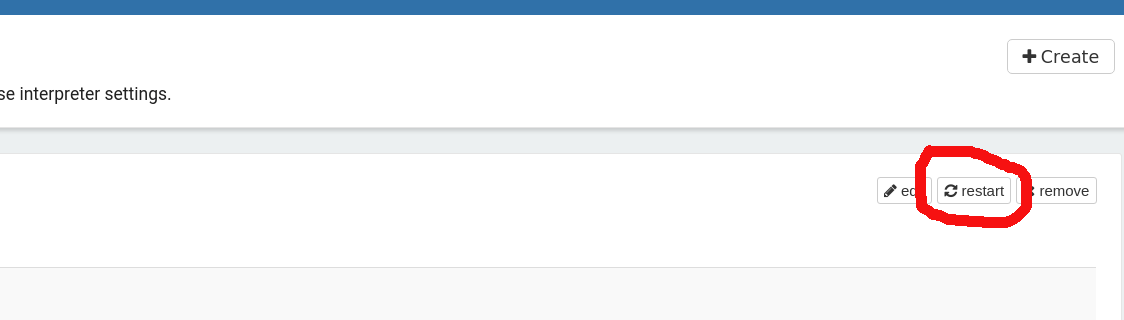 Click on "restart" for changes to take effect
Click on "restart" for changes to take effect
To avoid this, always close the StreamingContext but leave the underlying SparkContext alive:
ssc.stop(stopSparkContext=false, stopGracefully=true)
java.lang.IllegalStateException: Adding new inputs, transformations, and output operations after stopping a context is not supported
You have probably stopped the SparkContext; you need to restart the SparkInterpreter. See the bullet point above for a solution.