Pandas Dataframe Examples: Duplicated Data
Last updated:
- Show duplicated rows
- Show duplicated rows including original rows
- List duplicates
- Number of duplicated rows
- Duplicate count
- Drop duplicates
- Drop duplicates based on some columns only
- Drop all rows that have duplicates or are duplicates
- Mark duplicate rows with flag column
- Flag duplicate rows
- Arbitrary keep criterion
All code available on this jupyter notebook
Show duplicated rows
I.e. show rows that are duplicates of existing rows.
import pandas as pd
df = pd.DataFrame({
'title': ['foo','bar','baz','baz','foo','bar'],
'contents':[
'Lorem ipsum dolor sit amet.',
'Lorem ipsum dolor sit amet.',
'Lorem ipsum dolor sit amet.',
'Consectetur adipiscing elit.',
'Lorem ipsum dolor sit amet.',
'Lorem ipsum dolor sit amet.'
],
'year':[2010,2011,2000,2005,2010,2011]
})
df[df.duplicated()]
 Rows 1 and 5 are duplicates
Rows 1 and 5 are duplicates
 Show only duplicated rows
Show only duplicated rows with
df[df.duplicated()]
Show duplicated rows including original rows
Use df[df.duplicated(keep=False)].
This shows both duplicated and original rows.
import pandas as pd
df = pd.DataFrame({
'title': ['foo','bar','baz','baz','foo','bar'],
'contents':[
'Lorem ipsum dolor sit amet.',
'Lorem ipsum dolor sit amet.',
'Lorem ipsum dolor sit amet.',
'Consectetur adipiscing elit.',
'Lorem ipsum dolor sit amet.',
'Lorem ipsum dolor sit amet.'
],
'year':[2010,2011,2000,2005,2010,2011]
})
df[df.duplicated(keep=False)]
 Source dataframe
Source dataframe
 Using
Using keep=False means that both duplicates and the original
rows are displayed
List duplicates
See above Show duplicated rows
Number of duplicated rows
In other words, the number of rows that are duplicates of other existing rows.
Use len(df[df.duplicated()])
import pandas as pd
df = pd.DataFrame({
'title': ['foo','bar','baz','baz','foo','bar'],
'contents':[
'Lorem ipsum dolor sit amet.',
'Lorem ipsum dolor sit amet.',
'Lorem ipsum dolor sit amet.',
'Consectetur adipiscing elit.',
'Lorem ipsum dolor sit amet.',
'Lorem ipsum dolor sit amet.'
],
'year':[2010,2011,2000,2005,2010,2011]
})
len(df[df.duplicated()])
# >>> 2
Duplicate count
See above: number of duplicated rows
Drop duplicates
Results will depend on how the dataframe is sorted.
Use df.drop_duplicates().
The first row will be kept and the duplicates will be dropped.
import pandas as pd
df = pd.DataFrame({
'title': ['bar','bar','baz','baz','foo','foo'],
'contents':[
'Sed mollis tempor accumsan.',
'Sed mollis tempor accumsan.',
'Nullam et feugiat turpis, non condimentum dolor.',
'Aenean eu aliquam nunc.',
'Lorem ipsum dolor sit amet.',
'Lorem ipsum dolor sit amet.'
],
'year':[2010,2010,2005,2005,2011,2011]
})
df.drop_duplicates()
 By default, rows are considered
By default, rows are considered duplicates if values in all columns
(except the index) are identical.
 AFTER: dropped duplicated rows
AFTER: dropped duplicated rows
Drop duplicates based on some columns only
In other words, use only a subset of columns to define which rows are duplicates.
import pandas as pd
df = pd.DataFrame({
'title': ['bar','bar','baz','baz','foo','foo'],
'contents':[
'Sed mollis tempor accumsan.',
'Sed mollis tempor accumsan.',
'Nullam et feugiat turpis, non condimentum dolor.',
'Aenean eu aliquam nunc.',
'Lorem ipsum dolor sit amet.',
'Lorem ipsum dolor sit amet.'
],
'year':[2010,2010,2005,2005,2011,2011]
})
# only consider title and year when defining duplicates
df.drop_duplicates(subset=['title','year'])
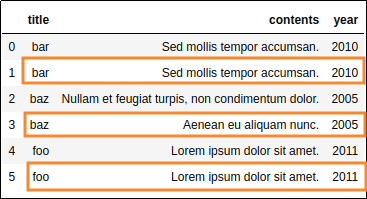 If we only take into account
If we only take into account columns title and year, then
these rows are duplicates
 By setting only
By setting only title and year to the subset parameter, we have a more
aggressive duplicate filter, which ends
dropping more rows
Drop all rows that have duplicates or are duplicates
I.e. if there are two identical rows, this will drop both from the dataframe.
Use df.drop_duplicates(keep=False)
import pandas as pd
df = pd.DataFrame({
'title': ['bar','bar','baz','baz','foo','foo'],
'contents':[
'Sed mollis tempor accumsan.',
'Sed mollis tempor accumsan.',
'Nullam et feugiat turpis, non condimentum dolor.',
'Aenean eu aliquam nunc.',
'Lorem ipsum dolor sit amet.',
'Lorem ipsum dolor sit amet.'
],
'year':[2010,2010,2005,2005,2011,2011]
})
df.drop_duplicates(keep=False)
 These rows either have duplicates
These rows either have duplicates or ARE duplicates themselves
 Setting keep=False means that you want to
Setting keep=False means that you want to keep neither the original rows
nor the duplicates.
Mark duplicate rows with flag column
Often, it's better to mark bad rows in a dataframe instead of deleting them.
This helps keep track of what modifications were done from the raw data until the processed dataframe.
Use df.assign() to create a new is_duplicate column:
import pandas as pd
df = pd.DataFrame({
'title': ['bar','bar','baz','baz','foo','foo'],
'contents':[
'Sed mollis tempor accumsan.',
'Sed mollis tempor accumsan.',
'Nullam et feugiat turpis, non condimentum dolor.',
'Aenean eu aliquam nunc.',
'Lorem ipsum dolor sit amet.',
'Lorem ipsum dolor sit amet.'
],
'year':[2010,2010,2005,2005,2011,2011]
})
# assign doesnt happen in place
df=df.assign(
is_duplicate= lambda d: d.duplicated()
).sort_values(['title','contents','year']).reset_index(drop=True)
df
 Source dataframe
Source dataframe
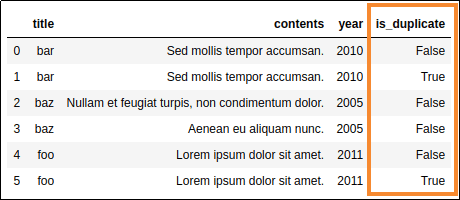 Using a helper column aids in keeping
Using a helper column aids in keeping track of data lineage.
Note that all columns were used
to define duplicates
Flag duplicate rows
See above: Mark duplicate rows with flag column
Arbitrary keep criterion
There's no out-of-the-box way to do this so one answer is to sort the dataframe so that the correct values for each duplicate are at the end and then use drop_duplicates(keep='last')
Example: drop duplicated rows, keeping the values that are more recent according to column year:
import pandas as pd
df = pd.DataFrame({
'title': ['bar','bar','baz','baz','foo','foo'],
'contents':[
'Sed mollis tempor accumsan.',
'Sed mollis tempor accumsan.',
'Nullam et feugiat turpis, non condimentum dolor.',
'Aenean eu aliquam nunc.',
'Lorem ipsum dolor sit amet.',
'Lorem ipsum dolor sit amet.'
],
'year':[2009,2019,2005,2005,2015,1995]
})
df.sort_values(
['title','contents','year']
).drop_duplicates(subset=['title','contents'],keep='last')
 Source dataframe: these have the
Source dataframe: these have the same title and contents, but
one is newer
 Only the most recent information
Only the most recent information for each duplicated group was kept.