Paper Summary: A New Probabilistic Model for Title Generation
Last updated:Please note This post is mainly intended for my personal use. It is not peer-reviewed work and should not be taken as such.
WHAT
A framework for creating titles for documents, following different strategies than those found in earlier (as of 2002) articles.
WHY
Because they find 2 problems in previous solutions:
Using a language model to measure the syntatic correctness of a given word sequence gives too much weight to common words (e.g. pronouns), which are rarely words that capture the semantics of a document.
Using the whole document to select words from wrongly assumes that all parts of the document are equally relevant in determining the overall theme of a document.
HOW
They assume the existence of a hidden state1 called an information source from which both the document itself and the title sample from. These models are estimated assuming independence between parameters.
CLAIMS
Previous (as of 2002) approaches for text generation follow a 2-phase process:
- 1) Word selection phase
- 2) Word ordering phase (of words selected in step 1)
- Authors claim the new model beats the old model (no hidden state) with respect to both objective and subjective evaluation metrics.
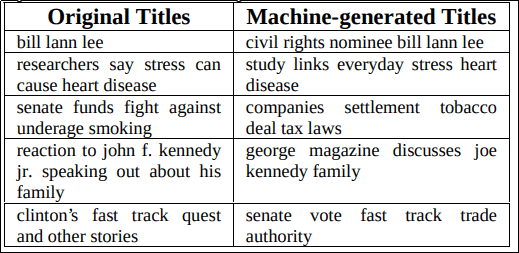 Selected pairs of original/automatically-
Selected pairs of original/automatically-NOTES
Results are measured using an objective measure (F-score) between the original text and the generated texts but also a subjective measure is used whereby human subjectives are asked to rate the generated titles in a scale of 1-5 according to how fitting they are.
A word's TF-IDF score is used as a proxy for that word's rarity.
The author's model the relationship between a document and its title as a translation from a source, verbose language into a target, more concise language.
Authors affirm that there is a difference between title generation and other similar tasks like automatic text summarization and keyword extraction.
1: As in Hidden Markov Models, for instance.