Machine Learning and Data Science: Generally Applicable Tips and Tricks
Last updated:
- Decide on business metrics before thinking about data science/machine learning
- Good Exploratory Analysis is sometimes all you need
- If it's too costly to calculate something, estimate it
- Ratios are usually more important than raw counts
- Try things out even if you are not sure if they're theoretically sound
- Do unsupervised training on your unlabelled data before supervised tasks
WIP Alert This is a work in progress. Current information is correct but more content may be added in the future.
Decide on business metrics before thinking about data science/machine learning
It's useless to spend time training a machine learning model, or analyzing data if the problem to be solved adds no values to your organization, or if you can't tell whether it's helped anything.
You need to think beforehand about how you'll measure how good or bad your model is. This helps you optimize your time because you are making sure that the problem you are trying to solve is actually having an effect on the bottom line.
You need at least to set up metrics that you can collect before and after introducing your model, such as:
Clicktrough rate: what percentage of people click on a link that's been suggested to them by your recommender system? What was that metric like before?
Time spent on website: what was the average amount of time users spent on your website before you started recommending content? Has it gone up?
Of course, for anything non-trivial, A/B Testing is the way to measure your model's effectiveness more accurately.
Good Exploratory Analysis is sometimes all you need
TODO
If it's too costly to calculate something, estimate it
Sometimes you need to calculate quantities with many operations. In many settings, the computational cost of calculating things precisely is very high, while you can get a reasonably good estimate quickly.
You can generally trade off precision for computational cost
This is sometimes the case when dealing with probabilities, since you often need to work out a complex denominator to force results to add up to 1 (so they can be interpreted as mutually exclusive events in a probabilistic setting).
Some examples:
If you need a a value which is a mean over all input vectors, do a mean over a random sample of those vectors. You can vary the sample size until you're happy with the precision.
Likewise, instead of estimating a given quantity precisely, it may be much easier to compute a bound (lower or upper, or both) for that instead, and it may be enough for the task at hand.
Ratios are usually more important than raw counts
The importance of some event is only calculable when measured against some sort of context.
This helps people calculate the value something has better than with its raw amount. This is generally more useful in a business setting.
For instance:
The total number of people who made purchases in an online store says very little.
The ratio between the total number of people who made purchases and the total number of people who just visited the store (and didn't buy anything) is a much more relevant metric.
This is so important there's a name fot it: it's called conversion.
The total distance travelled by a car sure is an important metric, but it doesn't say much unless you say how long it took.
Distance / Time = Velocity.
Both a Ferrari and a 1950's car can travel 200 miles. The fact that a Ferrari can do that in a single hour makes all the difference in the world.
Try things out even if you are not sure if they're theoretically sound
There are many examples in the literature of things that aren't strictly correct from a theoretical point of view, but nonetheless work well in practice.
Do unsupervised training on your unlabelled data before supervised tasks
Labelled data is data that has been classified by humans. This is what's generally used in supervised training algorithms.
Unlabelled data is less valuable, but it's much more abundant.
Unlabelled, raw, data is less valuable since you have no labels, but it's much more abundant. The recent spike in interest for neural network architectures is due, in part, to the advances in training large unsupervised models (such as stack RBM (Restricted Boltzmann Machines)), which learn multiple layers of features from unlabelled data.
Doing unsupervised "preprocessing" not only improves the accuracy and speed of your model, but it also acts as a regularizer, to the extent that you're using more data to train your model, thereby decreasing chances of overfitting.
The rationale for this is that the real world is what generates both unalabelled and labelled data, albeit in different quantities, as per the following picture (example for an image classification task):
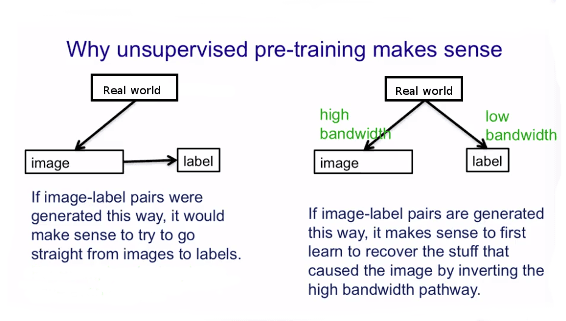 It is not captured image features (pixels) that generate the related image labels ("elephant", "car", etc). The real world generates both of them, so it's better to try and model that first. Adapted from Geoff Hinton's Coursera Class on NN.
It is not captured image features (pixels) that generate the related image labels ("elephant", "car", etc). The real world generates both of them, so it's better to try and model that first. Adapted from Geoff Hinton's Coursera Class on NN.