Pandas Dataframe Examples: Column Operations
Last updated:- Rename column
- Apply function to column names
- Apply function to column
- Create derived column
- Number of NaNs in column
- Get column names
- Get number of columns
- Change column order
- Drop column
- Drop multiple columns
- Append new column
- Check if column exists
- Insert column at specific index
- Convert column to another type
- Convert column to date/datetime
- map example
View all examples on this jupyter notebook
Rename column
To change just a single column name:
import pandas as pd
df = pd.DataFrame({
'name': ['alice','bob','charlie'],
'age': [25,26,27]
})
df.rename(columns={'name':'person_name'})
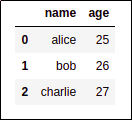 BEFORE: original dataframe
BEFORE: original dataframe
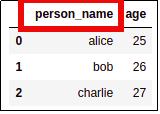 AFTER:
AFTER: name becomes person_name
To change multiple column names, it's the same thing, just name them all in the columns dictionary:
import pandas as pd
df = pd.DataFrame({
'name': ['alice','bob','charlie'],
'age': [25,26,27]
})
df.rename(columns={'name':'person_name','age':'age_in_years'})
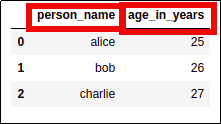 AFTER:
AFTER: name becomes person_name, age becomes age_in_years
Apply function to column names
Example: Make all column names uppercase
import pandas as pd
df = pd.DataFrame({
'name': ['alice','bob','charlie'],
'age': [25,26,27]
})
# convert column NAMES to uppercase
df.columns = [col.upper() for col in df.columns]
df
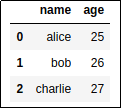 BEFORE: original dataframe
BEFORE: original dataframe
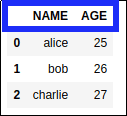 AFTER: colum names have been converted
AFTER: colum names have been converted to uppercase, but the data is still the same
Apply function to column
You can also use apply: Pandas Dataframes: Apply Examples
One way to apply a function to a column is to use map()
import pandas as pd
df = pd.DataFrame({
'name': ['alice','bob','charlie'],
'age': [25,26,27]
})
# convert all names to uppercase
df['name'] = df['name'].map(lambda name: name.upper())
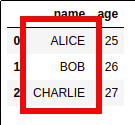 AFTER: applied function
AFTER: applied function upper() to all names
Create derived column
It's very common to add new columns using derived data. You just need to assign to a new column:
import pandas as pd
df = pd.DataFrame({
'name': ['alice','bob','charlie'],
'age': [25,26,27]
})
df['age_times_two']= df['age'] *2
df
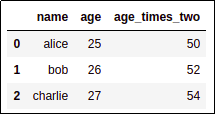 AFTER: you can apply vectorized functions
AFTER: you can apply vectorized functions like in numpy arrays
You can also use custom elementwise functions to help create the new column:
import pandas as pd
df = pd.DataFrame({
'name': ['alice','bob','charlie'],
'age': [25,26,27]
})
df["name_uppercase"] = df['name'].map(lambda name: name.upper())
df
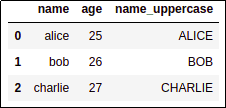 AFTER: derived column is appended to the dataframe
AFTER: derived column is appended to the dataframe
Number of NaNs in column
.isnull()considers bothnp.NaNandNoneas null values
Use .isnull() to check which values are null/NaN and then call .sum()
import pandas as pd
df = pd.DataFrame({
'name': ['alice','bob','charlie'],
'age': [25,26,np.nan],
'state': ['ak',np.nan,None]
})
print(df['name'].isnull().sum())
# 0
print(df['age'].isnull().sum())
# 1
print(df['state'].isnull().sum())
# 2
Get column names
Use df.columns.values:
import pandas as pd
df = pd.DataFrame({
'name': ['alice','bob','charlie'],
'age': [25,26,27],
'state': ['ak','ny','dc']
})
print(df.columns.values)
# ['age' 'name' 'state']
Get number of columns
Use len(df.columns.values) (ignores the index column):
import pandas as pd
df = pd.DataFrame({
'name': ['alice','bob','charlie'],
'age': [25,26,27],
'state': ['ak','ny','dc']
})
print(len(df.columns.values))
# 3
Change column order
To reorder columns, just reassign the dataframe with the columns in the order you want:
import pandas as pd
df = pd.DataFrame({
'name': ['alice','bob','charlie'],
'age': [25,26,27],
'state': ['ak','ny','dc']
})
# reassign the dataframe, selecting the
# columns in the order you want
df = df[['name','age','state']]
df
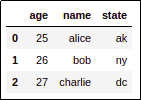 BEFORE: By default, Pandas displays
BEFORE: By default, Pandas displays columns in alphabetical order
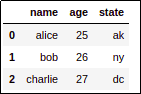 AFTER: But you just need to reassign the
AFTER: But you just need to reassign the dataframe with the columns in the order you want
Drop column
To delete a single column use df.drop(columns=['column_name'])
import pandas as pd
df = pd.DataFrame({
'name': ['alice','bob','charlie'],
'age': [25,26,27]
})
df.drop(columns=['age'])
 AFTER: Dropped column age
AFTER: Dropped column age
Drop multiple columns
To delete multiple columns, you can pass multiple column names to the columns argument:
import pandas as pd
df = pd.DataFrame({
'name': ['alice','bob','charlie'],
'age': [25,26,27]
})
df.drop(columns=['age','name'])
 AFTER: Deleted both columns,
AFTER: Deleted both columns, only the index column is left!
Append new column
In order to add a new column to a DataFrame, create a Series and assign it as a new column:
import pandas as pd
df = pd.DataFrame({
'name': ['alice','bob','charlie'],
'age': [25,26,27]
})
states = pd.Series(['dc','ca','ny'])
df['state'] = states
df
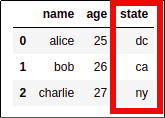 AFTER: Column is added following row order
AFTER: Column is added following row order
Check if column exists
import pandas as pd
df = pd.DataFrame({
'name': ['alice','bob','charlie'],
'age': [25,26,27]
})
candidate_names = ['name','gender','age']
for name in candidate_names:
if name in df.columns.values:
print('"{}" is a column name'.format(name))
# outputs:
# "name" is a column name
# "age" is a column name
Insert column at specific index
Call df.insert(<position>,<column_name>, <data>) on the dataframe:
import pandas as pd
df = pd.DataFrame({
'name': ['alice','bob','charlie'],
'age': [25,26,27]
})
column_data = pd.Series(['female','male','male'])
# starts at zero
position = 1
column_name = 'gender'
df.insert(position, column_name, column_data)
 AFTER: 0 is the first column,
AFTER: 0 is the first column, 1 is the second one, etc
Convert column to another type
Use astype(). Numpy types (such as 'uint8', 'int32', 'int64', etc) and python types (str, int, etc) are supported
import pandas as pd
df = pd.DataFrame({
'name': ['alice','bob','charlie'],
'age': [25,26,27]
})
print(df2['age'].dtype)
# 'int64'
df2['age'] = df2['age'].astype(str)
print(df2['age'].dtype)
# 'object'
df2['age'] = df2['age'].astype(np.uint8)
print(df2['age'].dtype)
# 'uint8'
Convert column to date/datetime
Use pd.to_datetime(string_column):
import pandas as pd
df = pd.DataFrame({
'name': ['alice','bob','charlie'],
'date_of_birth': ['10/25/2005','10/29/2002','01/01/2001']
})
df['date_of_birth'] = pd.to_datetime(df['date_of_birth'])
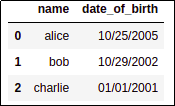 BEFORE: column is of type 'object'
BEFORE: column is of type 'object'
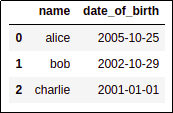 AFTER: column 'date_of_birth' is
AFTER: column 'date_of_birth' is now of type 'datetime' and you can
perform date arithmetic on it
If your dates are in a custom format, use format parameter:
View all possible formats here: python strftime formats
import pandas as pd
df = pd.DataFrame({
'name': ['alice','bob','charlie'],
'date_of_birth': ['27/05/2001','16/02/1999','25/09/1998']
})[['name','date_of_birth']]
df['date_of_birth'] = pd.to_datetime(df['date_of_birth'],format='%d/%m/%Y')
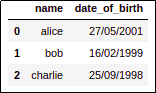 BEFORE: In some countries, dates are often
BEFORE: In some countries, dates are often displayed in a day/month/year
format
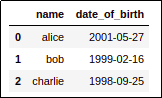 AFTER: Just pass the
AFTER: Just pass the format parameter so that pandas knows what format your
dates are in
map example
Use .map() to create derived columns:
import pandas as pd
df = pd.DataFrame({
'name': ['alice','bob','charlie'],
'age': [25,26,27]
})
# add a new column to the dataframe
df['name_uppercase'] = df['name'].map(lambda element: element.upper())
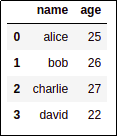 BEFORE: original dataframe
BEFORE: original dataframe
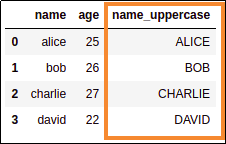 AFTER: using .map() is a very
AFTER: using .map() is a very common way to add derived columns
to a dataframe
map vs apply: time comparison
One of the most striking differences between the .map() and .apply() functions is that apply() can be used to employ Numpy vectorized functions.
This gives massive (more than 70x) performance gains, as can be seen in the following example:
Time comparison: create a dataframe with 10,000,000 rows and multiply a numeric column by 2
import pandas as pd
import numpy as np
# create a sample dataframe with 10,000,000 rows
df = pd.DataFrame({
'x': np.random.normal(loc=0.0, scale=1.0, size=10000000)
})
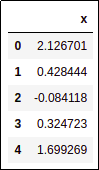 Sample dataframe for benchmarking
Sample dataframe for benchmarking (top 5 rows shown only)
Using map function multiply 'x' column by 2
def multiply_by_two_map(x):
return x*2
df['2x_map'] = df['x'].map(multiply_by_two)
# >>> CPU times: user 14.4 s, sys: 300 ms, total: 14.7 s
# >>> Wall time: 14.7 s
Using apply function multiply 'x' column by 2
import numpy as np
def multiply_by_two(arr):
return np.multiply(arr,2)
# note the double square brackets around the 'x'!!
# this is because we want to use DataFrame.apply,
# not Series.apply!!
df['2x_apply'] = df[['x']].apply(multiply_by_two)
# >>> CPU times: user 80 ms, sys: 112 ms, total: 192 ms
# >>> Wall time: 188 ms
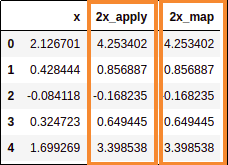 Both map and apply yielded identical results
Both map and apply yielded identical results but the apply version was
70 times faster!