Paper Summary: Long Short-Term Memory-Networks for Machine Reading
Last updated:Please note This post is mainly intended for my personal use. It is not peer-reviewed work and should not be taken as such.
WHAT
Authors present an enhancement to how Attention is used in LSTMs, namely intra-attention or self-attention
They name it LSTMNs (Long Short-Term Memory Networks)1
HOW
In the LSTMN, the attention mechanism is added within the encoder (whereas in previous implementations it was added between the encoder and the decoder.)
Authors present two ways of integrating self-attention into LSTMs:
"Shallow Fusion": Use encoder-decoders and both use self-attention
"Deep Fusion": Use encoder-decoders and they use both inter-attention and self-attention
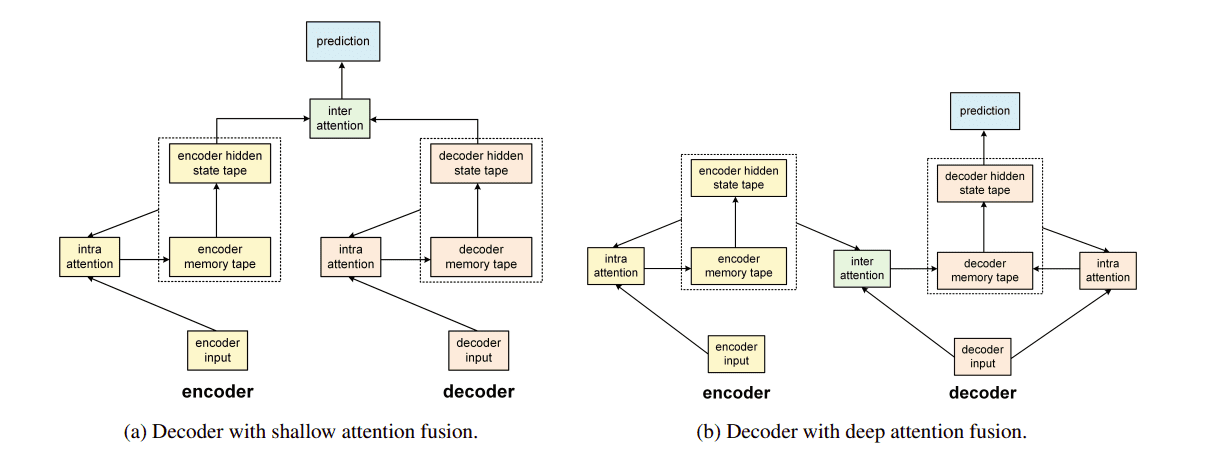 On the left the Shallow Fusion integration technique and on the right
On the left the Shallow Fusion integration technique and on the right the Deep Fusion technique, where the encoder and the decoder
have both regular and self-attention
WHY
Traditional LSTMs with Attention may have a hard time storing knowledge that:
Requires it to store long sequences of text
Has structure (other than sequential ordering)
Traditional LSTMs have to recursively compress the knowledge in its memory cells after each iteration; this makes it harder for them to represent finer concepts accurately.
CLAIMS
Language modelling
- LSTMN beats traditional LSTMs with the same memory (as measured by perplexity)
Sentiment Analysis
- LSTMN beats traditional LSTMs on this task (measured by accuracy)
- But a CNN (called T-CNN) was better than both LSTMN and traditional LSTMS
Natural Language Inference (textual entailment)
- LSTMNs beats traditional LSTMs on this task (measured by accuracy)
QUOTES
- On self-attention: "A key idea behind the LSTMN is to use attention for inducing relations between tokens"
NOTES
Model is tested in the following tasks: language modeling, sentiment analysis, and natural language inference
The term "self-attention" doesn't seem to show up in this article - they call it "intra-attention" (as opposed to Bahdanau's "inter-attention")
There was no pre-training (self-supervised or otherwise)
- But they used pretrained embeddings
References
Footnotes
1: "Memory networks" refer back to Weston et al 2015: Memory Networks