Paper Summary: ULMFIT: Universal Language Model Fine-tuning for Text Classification
Last updated:- WHAT
- WHY
- HOW
- Discriminative Fine-tuning
- Slanted Triangular Learning Rate Schedule
- Gradual unfreezing
- CLAIMS
- QUOTES
- NOTES
- MY 2¢
Please note This post is mainly intended for my personal use. It is not peer-reviewed work and should not be taken as such.
WHAT
Authors introduce a new way to fine-tune pre-trained language models so that they can be optimized with just a few extra labelled examples from the target domain while still outperforming models trained from scratch on the target domain.
WHY
Because the previous methods of fine-tuning language models either 1) only acted on the last layer of the LM or 2) needed too many examples to be able to successfully generalize to the target domain.
HOW
The procedure is as follows:
1) (Unsupervised) Train a simple LM on a large body of text, on any source domain
2) (Unsupervised) Fine-tune the LM from step 1 using data from the target domain using discriminative fine-tuning and slanted triangular learning rates.
- This step uses discriminative fine-tuning and slanted triangular learning rates.
3) (Supervised) Adding two new classifier layers (e.g. ReLU and a softmax) and fine-tune it to the actual task.
- This step uses discriminative fine-tuning, slanted triangular learning rates and gradual unfreezing of classifier layers
Discriminative Fine-tuning
Discriminative fine-tuning means using a larger learning rate for the last layer and decrease the learning rate for each layer, consecutively until the first.
For example: use \(\eta=0.01\) for the last (most specific) layer, \(\eta=0.005\) for the second-last, etc.
Slanted Triangular Learning Rate Schedule
Slanted Triangular Learning Rate is a learning rate schedule; the maximum learning rate (last layer) grows linearly until it maxes out and then starts to be lowered
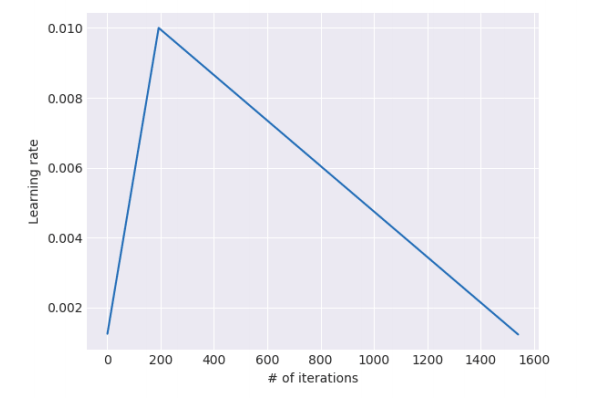 How the learning rate changes with the number of iterations
How the learning rate changes with the number of iterations Don't confuse this with the activation function
Gradual unfreezing
Refers to unfreezing one layer per epoch, starting at the last (most specific) layer.
Then, for each new epoch, one extra layer is added to the set of unfrozen layers, and these get to be fine-tuned in that epoch.
CLAIMS
Slanted Triangular LR is better for performance than the original triangular schedule1
They report gains on then SOTA (using less data, against more sophisticated models) on 3 text classification tasks: sentiment analysis (IMDB, Yelp), question classification (TREC6) and topic classification (AGNew, DBPedia)
QUOTES
- "Language modeling can be seen as the ideal source task and a counterpart of ImageNet for NLP: It captures many facets of language relevant for downstream tasks, such as long-term dependencies, hierarchical relations and sentiment. [...] it provides data in near-unlimited quantities for most domains and languages."
NOTES
Inductive vs Transductive Transfer Learning: These are not terms you hear everyday but the meaning is simple:
- in inductive transfer learning you are actually trying to train or fine-tune a model so that it is expected to perform well on a holdout dataset (just like regular supervised learning)
- in transductive transfer learning, the problem is somewhat simpler: here we just propagate characteristics (e.g. labels, frequency counts, word-pair similarities) from one source domain/dataset to a target domain/dataset. This can be done with a simple algorithm like kNN.
Hypercolumns
- This is one way to transfer features from pre-trained models (NLP or CV). Instead of just using the last layer of a LM as a feature representaion, a combination (e.g. concatenation) of all layers in the LM is used instead. (Apparently in CV it isn't used anymore, full end-to-end fine-tuning is done instead)
The trained language model is a simple Uni-LSTM, with no attention mechanism. (but they also compared against a Bi-LSTM LM, showing gains in performance, with the penalty of longer training times.)
The last 2 classifier layers don't just take the hidden state of the previous layer, but they also use the
AvgPooland theMaxPoolof the hidden states of all previous time-steps.
MY 2¢
Very nice to see that the authors only needed a fraction of training examples to reach the same performance one would have training a classifier from scratch on the full documents.
Being able to achieve the same results using 10x, 100x or 500x less training examples is a massive win.
It wasn't clear which layers were left unfrozen in the classifier fine-tuning task.
1: The triangular schedule for learning rates was suggested in another article, but the original triangle was not slanted (i.e. it was symmetrical)