Project Review: Generating Article Titles from Keywords
Last updated:
- Problem setting
- Technical overview of solution
- Data preprocessing cycles
- Attempt 1: using the final preprocessed data
- Attempt 2: replacing the keyword with a special token in title
- Lessons learned
Problem setting
We had 2 sets of data:
Dataset 1) Curated keyword, title pairs, provided by the client (around 300,000 rows)
Dataset 2) Search engine data dump1, from DataForSeo.com (multiple terabytes of data)
Client required an API-accessible system that would receive keywords as inputs and it would output a list of 10 options of titles for articles for that keyword.
Titles should be evergreen, i.e. they should not be bound to specific events, dates or locations, so that it can be used for many years.
Technical overview of solution
We created a simple Seq2Seq. encoder-decoder architecture using LSTMs using Tensorflow 1.15 (initially).
We chose to start with a word-based2 Seq2Seq architecture (i.e. it generates words one by one instead of generating chars one by one) because it is faster and simpler.
Training model
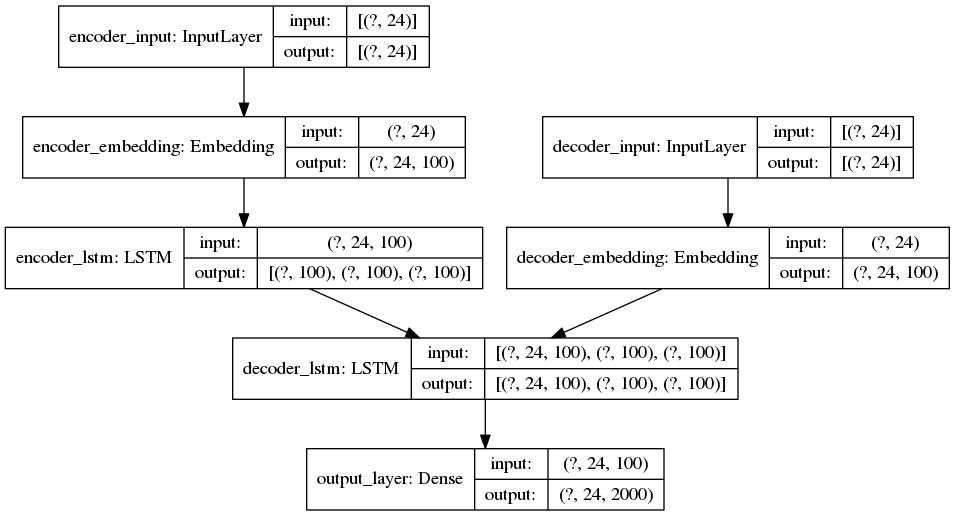 24 is the maximum sequence size.
24 is the maximum sequence size. 100 is the number of dimensions in the
embedding layer
Inference models
Inference in Seq2Seq is not just calling model.predict(), need to create an actual inference models:
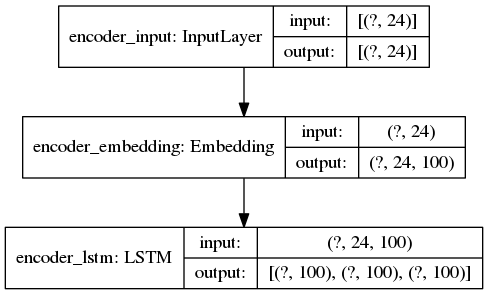 Inference model for the encoder
Inference model for the encoder
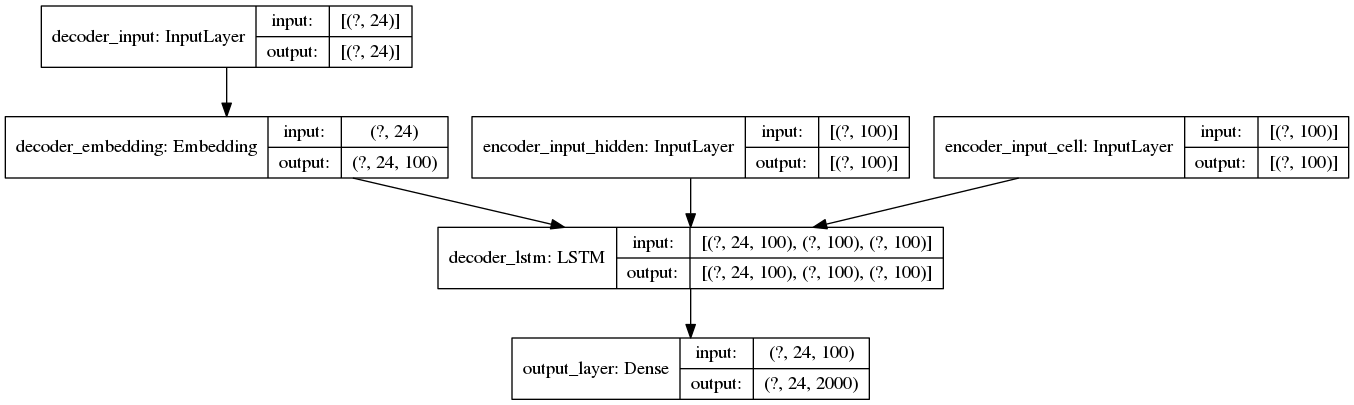 Inference model for the decoder
Inference model for the decoder step in the encoder-decoder
architecture
Data preprocessing cycles
We chose to merge the two datasets (as explained above).
Dataset 1 was much smaller but it was manually curated so it had high quality data.
Dataset 2 was a mess. It was literally a large sample of search engine queries and the top 98 results for each, during some days. There were several data cleaning/filtering cycles, for example:
- Only keep queries that are relatively common, to weed out noise
- Only keep the top 10 results per query, to weed out results from the long tail
- Only keep queries that have been used in many different months (rather than at a given day only)
- Remove results from online classified websites (not evergreen)
- Remove results related to location (city names, neighbourhood names, etc)
- Remove results related to time and dates (days of the week, "last week")
- Remove results from adult websites
- Replace numbers, country names, state names, by static tokens
- Lowercase, remove special characters, tokenize points, commas, etc.
Attempt 1: using the final preprocessed data
I.e., the dataset after the preprocessing cycles mentioned above.
As a first attempt, we trained the Seq2Seq architecture using the keyword (or search engine query) as features and the article title as the target.
In other words, we trained a model that should learn how to produce the article title (sequence of words) from the keywords. All words have been encoded as their FastText embeddings.
Attempt 2: replacing the keyword with a special token in title
This required us to filter the dataset so that only cases where the keyword appears verbatim in the title are considered
The previous attempt didn't work so well so we tried a new approach.
Instead of using the data as in the previous attempt, we replaced the keyword with a static token in the title:
 This is the dataset, as
This is the dataset, as used in Attempt 1
 For Attempt 2, we replaced the
For Attempt 2, we replaced the occurrences of the keyword by a
static token in the title
The results were now much better, as we expected: the model was much better at generating good titles (we had to replace it back by the keyword to arrive at the final sequence).
Lessons learned
Here are a couple of lessons learned while taking part in this project:
Using search engine dumps is hard
A large proportion of search queries and results is related to adult content or otherwise stuff you do not want to include in your dataset
The distribution of sites in the search results is extremely skewed. Online classifieds, price comparison websites, and other content aggregators are responsible for a large part of results.
Many people misspell things so you need to fix the text in many cases
- In the case of latin languages, they also omit things like accents and cedils and stuff like that so you also need to fix those
Inference in Seq2Seq models is more complex
Inference in Seq2Seq models is not a simple matter of calling .predict() on a fitted model. You actually need to build an inference model for it.
The inference loop for a word-based Seq2Seq system goes like this:
1) Generate the distribution over the next sequence element (i.e. the next word)
2) Update the model state
3) Sample an element from the distribution generated in 1)
4) If the sampled element in 3) is EOS, stop. Else, go back to 1)
Once you have generated an EOS (End-of-sequence) marker, you have reached the end of this particular sentence.
Temperature is a tradeoff between precision and "diversity"
A good way to remember: Low temperature => cold => spiky ice => pointy probability distributions => precision over creativity
The temperature term is what defines how creative the sequences generated will be.
You want to control this term and find the sweet spot for your use case.
If you set the temperature value very close to 0.0, all sequences generated by the model will be the same. This is not what you want when you need multiple different options of titles.
On the other hand, if you set a higher value (e.g. over 1.0), the generated sequences will be so different from what the model learned in the training set that they will likely be garbage, badly worded, wrong syntax, etc.
Porting code from Tensorflow 1.x to 2 is not so hard
Just a few changes were necessary.
Using CuDNNLSTM is massively faster than the default option
This version of the LSTM layer natively uses NVIDIA's CUDA drivers, resulting in massive (in this case, 20x) reduced time for training the model.
NLP work in languages other than English has an additional layer of difficulty
Not much high-quality prebuilt language models, embeddings and resources
Need to "clean" the data, removing things like diacritics and non-UTF-8 characters so that your normal stack will work OK
Text encodings are a pain when dealing with non English text.
- ftfy is an awesome library to help you in these cases.
It is not easy to measure performance of generative models
While there are metrics to see if a given generated text There is no "ground truth" to evaluate a generated text against.
It is easy to see large gains in the quality of generated text but it is harder to see if incremental changes to the architecture, different data preprocessing, etc are having any real effect.
FastText can be used to generate embeddings for unseen words
The FastText library for embeddings can generate vectors even for unknown words.
This is possible because the embeddings are generated from subword information (like syllables), so it's possible to infer what the embedding for an unseen word is (based on similar words whose embeddings are known).
Print an inference sample every few epochs
Also checkpoint the model so you don't lose your work if you're forced to stop it early!
It really isn't pleasant when you wait 24 hours to test a new strategy and the result is poor.
One way to try and debug this is to generate text for a fixed input every few epochs.
This way, you can visually see if the quality is gradually getting better as new train epochs are added.
1: This type of data is called SERP (Search Engine Results Page)
2: The other way to do this is to train a character-based LSTM, where one letter (or whitespace) is generated at a time. This usually makes better models but is slower.