Project Review: Text Classification of Legal Documents
Last updated:- Help clients help you
- Careful with assumptions
- Accuracy isn't a good metric for skewed problems
- Some aspects of the problem don't need to be modelled at all
- Use client knowledge to augment vectorizers
- Exploratory analysis adds value in and of itself
- Look at individual data points
- Look at model results
- NaNs, zeros and empty strings
- XGBoost is a good default choice
- Use calibrated classifiers
- Wrap key preprocessing steps into methods
This post is mainly geared towards data scientists using python, but users of other tools should be able to relate.
Help clients help you
You just cannot assume the client knows what they want. It’s your job to help them discover.
Frequent deploys of intermediate versions of the project helps the clients help you;
- After looking at the initial versions, they will better understand what it’s about and they will be able to better communicate what they want.
Careful with assumptions
The assumptions at training time must be the same as at use time. Otherwise, we can't really trust any generalization we may observe in test sets.
It's important to realise that starting to use ML signals a change in attitude for many companies. So they may start operating in a different way, in which case the test set won't be a good proxy for future data.
Accuracy isn't a good metric for skewed problems
This is not a new idea at all but it's useful to underline this because very often we just default to using accuracy without really thinking whether it's the right metric.
Some aspects of the problem don't need to be modelled at all
Sometimes you will find deterministic patterns in the data that do not need to be modelled at all.
In these cases, ifs/elses will be enough for you.
These are called rule-based systems and they need to be part of your arsenal.
Use client knowledge to augment vectorizers
Although vectorizers (like sklearn's TfidfVectorizer) do weigh terms wrt. to their relative rarity in the dataset, we can (and should) use client knowledge to help produce better features.
One way to do this is to augment vectorized features; in other words, concatenate features found by a vectorizer trained on the training data with features found by a static vectorizer instantiated with the words provided by clients.
To use a fixed vocabulary with a vectorizer, use parameter vocabulary in the vectorizer constructor, passing the list of words (or phrases) you want it to detect.
Exploratory analysis adds value in and of itself
Always do exploratory analysis, to answer questions such as:
- how many samples per day/month/year?
- how many samples per class? How skewed is your data?
Get good at pandas and matplotlib
Means and averages can trick you
- Use standard deviation to see how spread out your data is
- Better yet, plot histograms.
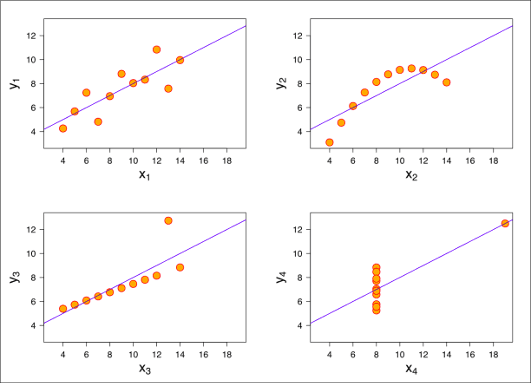 Anscombe's Quartet: All 4 datasets have the same: mean of x,
Anscombe's Quartet: All 4 datasets have the same: mean of x, mean of y, variance of x, variance of y, correlation between x and y
and the same linear regression line
Look at individual data points
In addition to regular EDA, look at some individual data points.
Use df.sample() a couple of times, let your brain figure out some interesting patterns in the raw data.
Look at model results
Say you have a complex pipeline of preprocessing, feature extraction, normalization, etc.
Your brain is fallible. Perform sanity-checks.
Have the model predict the classes for an instance you know the result for. Verify it matches.
Pass a single instance through the whole preprocessing pipeline.
- Does the output make sense? Does it match the training pipeline?
Sample rows from the dataframes at each stage, look at a few examples. Does it make sense?
Another to do this, of course, is by having proper testing infrastructure for your models.
NaNs, zeros and empty strings
Numpy NaNs and other ways to signal non-existence such as 0, empty strings, empty lists, etc, sometimes get mixed up.
They can trick you into wrong results.
Example: you want to count the ratio of samples with no data for a text column so you use df[df['my_text_column'].isnull()], but you will get wrong results because you used empty strings ("") to signal when there was no text, and this isn't picked up by the isnull() method of course!
XGBoost is a good default choice
XGBoost is a good default choice for classifiers
- No feature preprocessing is needed
- It can handle null/missing values
- You can easily view feature importance. This is important because it helps clients understand what is going on.
Use calibrated classifiers
When you use calibrated classifiers for probabilistic classification, a score of 0.7 means that the probability that this target is TRUE is exactly 70%.
It’s better to use classifiers that natively output probabilities if possible. This helps users trust your results.
Some classifiers are calibrated out of the box (e.g. Logistic Regression) but others (such as XGBoost) can be made to use calibrated objective functions.
- And even if you have a model that can't, you can always calibrate them.
- Read this post on this very topic: Introduction to AUC and Calibrated Models with Examples using Scikit-Learn
Wrap key preprocessing steps into methods
This makes it easier to make sure the code you use at training time is the exact same code you use at prediction time!
Use Pipelines1 whenever possible because it allows you to put the whole preprocessing and training steps into a single object.