Spark Dataframe Examples: Pivot and Unpivot Data
Last updated:- Pivot vs Unpivot
- Pivot with .pivot()
- Unpivot with selectExpr and stack
- Heads-up: Pivot with no value columns trigger a Spark action
Examples use Spark version 2.4.3 and the Scala API
View all examples on a jupyter notebook here: pivot-unpivot.ipynb
Pivot vs Unpivot
| Pivot | Unpivot |
|---|---|
| Turn tall dataframes into wide dataframes | Wide dataframes into tall dataframes |
| Turn rows into columns | Turn columns into rows |
Here's a rough explanation for what both operations achieve:
Pivot: Turn rows into columns.
Unpivot: Turn columns into rows.
Pivot with .pivot()
val sourceDf = Seq(
("john", "notebook", 2),
("gary", "notebook", 3),
("john", "small phone", 2),
("mary", "small phone", 3),
("john", "large phone", 3),
("john", "camera", 3)
).toDF("salesperson","device", "amount sold")
val sourceDf = unpivotedDf
.groupBy("salesperson")
.pivot("device")
.sum("amount sold")
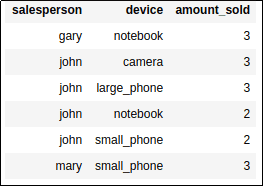
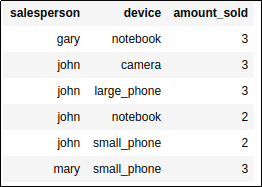 BEFORE: Each fact is on a
BEFORE: Each fact is on a separate row
 AFTER PIVOTING: Each different device
AFTER PIVOTING: Each different device gets a column and aggregates (in this
case sum) are shown
Unpivot with selectExpr and stack
Unpivot is the inverse transformation for pivot.
There's no equivalent dataframe operator for the unpivot operation, we must use selectExpr() along with the stack builtin.
Template: df.selectExpr("stack(<n_columns>, <col0_label>, <col0_value>, <col1_label>, <col1_value> ...)")
// using Option[Int] to help spark's type inference
val sourceDf = Seq(
("gary",None, None, Some(3),None),
("mary",None, None, None, Some(3)),
("john",Some(3),Some(3),Some(2),Some(2))
).toDF("salesperson", "camera", "large phone", "notebook", "small phone")
// select the row label column (salesperson) and apply unpivot in the other columns
val unpivotedDf = sourceDf
.selectExpr("salesperson","stack(4,'camera',camera,'large_phone',large_phone,'notebook',notebook,'small_phone',small_phone)")
.withColumnRenamed("col0","device") // default name of this column is col0
.withColumnRenamed("col1","amount_sold") // default name of this column is col1
.filter($"amount_sold".isNotNull) // must explicitly remove nulls
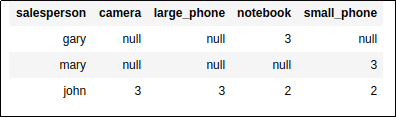 BEFORE: data is spread across columns
BEFORE: data is spread across columns
 AFTER UNPIVOTING: a row has been created for each
AFTER UNPIVOTING: a row has been created for each combination of the row label and the
stacked columns
Heads-up: Pivot with no value columns trigger a Spark action
| Action is triggered |
No action triggered |
|---|---|
df.groupBy('a').pivot('b') | df.groupBy('a').pivot('b', Seq('c','d','e')) |
The pivot operation turns row values into column headings.
If you call method pivot with a pivotColumn but no values, Spark will need to trigger an action1 because it can't otherwise know what are the values that should become the column headings.
In order to avoid an action to keep your operations lazy, you need to provide the values you want to pivot over, by passing the values argument.
1: Spark Architecture Overview: Clusters, Jobs, Stages, Tasks