Paper Summary: Exploring the Limits of Transfer Learning with a Unified Text-to-text Transformer
Last updated:Please note This post is mainly intended for my personal use. It is not peer-reviewed work and should not be taken as such.
 Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer Source
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer Source
WHAT
Authors create a framework to convert any NLP problem1 into a natural language format and use it to compare strategies to apply LLMs to NLP tasks.
The resulting model is called T5, short for "Text-to-Text Transfer Transformer".
They analyze how the performance of each task gets better as they add more parameters, more data, change the pretraining objective and the network architecture.
Authors were inspired by other attempts at unifying NLP tasks2
The C4 (Colossal Clean Crawled Corpus) corpus is released here.
HOW
They start by pre-training a standard Encoder-Decoder Transformer with Self-attention as detailed in Section 2.1 on a masked LM task on the C4 corpus.
They then re-run the flow, modifying one of the following elements:
1) Architecture: The basic Encoder-Decoder architecture. Using just the decoder as an LM, using a single transformer. Using a prefix-LM instead of a regular LM. Also parameter sharing configuration.
2) Model capacity: Varying the number of layers, parameters, and computation cycles
3) Objective function for pretraining: Vanilla LM trained on a chunk of text to predict the next chunk; then a modified masked LM function. Varies corruption strategies, corruption rates, and corrupted text length.
 Baseline variations on the objective function
Baseline variations on the objective function used by unsupervised pretraining.
Source: Raffel et al 2020.
4) Dataset type and size: Raw C4 baseline (unfiltered, unpreprocessed); preprocessed C4; News datasets; Reddit data; Wikipedia data, etc. Also truncated versions of datasets.
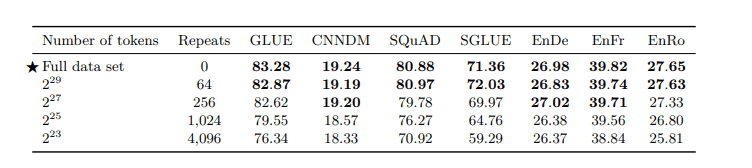 As expected, using larger versions of
As expected, using larger versions of the C4 dataset for pre-training
yields better performance.
Source: Raffel et al 2020.
5) Fine-tuning Strategies: Adapter layers; Gradual Unfreezing.
6) Pretraining Strategies: Pre-training then Fine-tuning; Multi-tasking.
Other Details
Text preprocessing is done with
SentencePiece(text is splits into a predetermined number of subword units)The pretraining objective is a masked language modeling task (instead of predicting the next token as in regular LM, this masks a token anywhere in the sentence and the model is trained to find out what token it was)
CLAIMS
Sharing parameters in Transformers: "Concurrent work (Lan et al.,2019) also found that sharing parameters across Transformer blocks can be an effective means of lowering the total parameter count without sacrificing much performance."
Denoising objectives work better: "... we confirm the widely-held conception that using a denoising objective always results in better downstream task performance compared to a language modeling objective."
Fine-tuning > Multitasking: Pretraining with Fine-tuning resulted in better performance than just multitasking. But the best alternative is to mix in some multi-task objectives into pretraining and then doing fine-tuning.
Managing computing resources: The most efficient way of adding extra computing power is to split it into more data and more training steps, equally, or else just invest it all into more data.
More capacity/data → better performance: Using more data and a higher capacity for T5 (authors tested up to 11 billion parameters) resulted in higher performance in all tasks.
- However, just adding tons of extra capacity (1T+) to the baseline models did not make it surpass T5 with 4 billion parameters.
T5 is cheap: Single models (such as T5) are cheaper to use than similar-capacity ensembles of models.
No SOTA on Translation tasks: The T5 model was not able to reach SOTA results in any Translation tasks
- But they did all pre-training on English-only datasets
- They claim that scale alone in an English-only dataset is not enough to surpass smaller models that use both languages in training sets.
QUOTES
T5 framework: "... the text-to-text framework allows us to directly apply the same model, objective, training procedure, and decoding process to every task we consider"
English generalized to other languages "Note that we only pre-train on English data, so in order to learn to translate a given model will need to learn to generate text in a new language."
- This is quite interesting. The model learns to generate text in a language it has never seen during pre-training, but just fine-tuned on.
Scale: "... scaling up may continue to be a promising way to achieve better performance. However, it will always be the case that there are applications and scenarios where using a smaller or less expensive model is helpful, for example when performing client-side inference or federated learning"
Relative embeddings: "Instead of using a fixed embedding for each position, relative position embeddings produce a different learned embedding according to the offset between the “key” and “query” being compared in the self-attention mechanism."
NOTES
The model is built on Tensorflow
The name of the task itself is just another word prepended to the input text the model takes... amazing.
Authors say that preventing validation data from leaking into the training sets is a major issue when dealing with massive-scale datasets. Makes sense.
Model Capacity: 11 billion Parameters
Fill-in-the-blanks-self-supervision is a generalization of vanilla (predict-the-next-word) pretraining used by other LLMs. (it's just a special case where the blank is at the end)
MY 2¢
Section 2.1 (The Model) is a pretty good overview of what a modern Transformer architecture instantiation looks like.
Interesting take here, about the quality of CommonCrawl data: "Unfortunately, the majority of the resulting text is not natural language. Instead, it largely comprises gibberish or boiler-plate text like menus, error messages, or duplicate text."
- Here, they also say how they preprocessed the data to arrive at higher-quality text for training. Been there, done that
"Language Models as knowledge bases" is a thing, it's being studied. The task on which these are tested is called "Closed-Book Q&A".
They cite an interesting paper that tried to represent every NLP task as span-extraction (just like the NLP Decathlon did it for Q&A)
1: Includes tasks such as question answering, translation, document summarization, sentiment classification, and document classification.
2: Including our previously summarized text Natural Language Decathlon which tries to cast all NLP tasks as instances of question-answering.