Paper Summary: Improving Language Understanding by Generative Pre-Training
Last updated:Please note This post is mainly intended for my personal use. It is not peer-reviewed work and should not be taken as such.
WHAT
This paper introduced the Open AI GPT Model, a semi-supervised strategy for enhancing the performance on multiple NLP tasks.
It is similar to ULMFit in that it performs an unsupervised pretraining step (learning a language model on a large corpus) and then fine-tunes for each downstream supervised task, but it uses a Transformer architecture rather than an LSTM.
WHY
Because Transformers are able to learn longer and more general sequence dependencies than LSTMs, thus having more capacity to learn from larger datasets.
HOW
GPT is composed of two steps:
1) an unsupervised pretraining step where a decoder-only Transformer is used to learn a Language Model on a very large dataset
2) a supervised step where the pretrained model has an extra linear layer added at the end, and this is trained with downstream task targets.
This approach is tested with 4 downstream supervised tasks, namely: Natural Language Inference (NLI), Question-Answering, Semantic Similarity and Text Classification.
Zero-shot learning
As unexpected as it seems, it's actually possible to get good results on supervised tasks with a model that was trained exclusively on unlabelled data (i.e. a language model). The GPT seems to be especially good at that, probably due to its use of Transformer architecture.
This is an extreme form of domain adaptation, called zero-shot learning. See below:
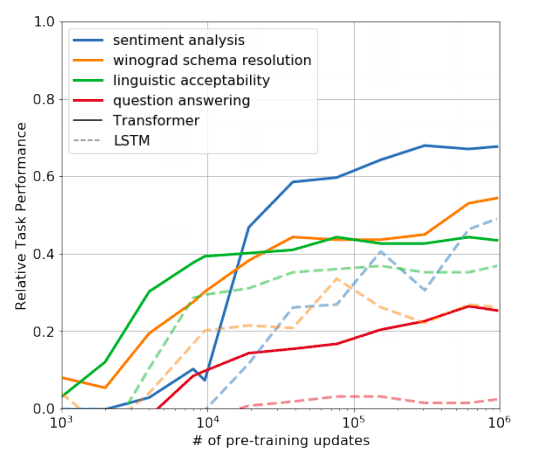 It is possible to reach up to 70% of the SOTA score on Sentiment
It is possible to reach up to 70% of the SOTA score on Sentiment Analysis with a pure unsupervised language model!! (thick blue line)
Source: Radford et al., 2018: Improving Language Understanding by Generative Pre-Training
CLAIMS
Beats State-of-the-Art in several tasks using default datasets: NLI/Textual Entailment, Question-Answering, Semantic Similarity and Text Classification.
Transformers work better than LSTMs because they are able to learn longer dependencies between pieces of text
Datasets with long sentences and plots (such as prose books) are better to train models because they contain longer-ranged dependencies (as opposed to other text datasets containing, for instance, tweets or even movie reviews).
QUOTES
- "Our setup does not require these target tasks to be in the same domain as the unlabeled [unsupervised] corpus."
NOTES
This is the paper that preceded GPT 2
Authors mention they use an auxiliary objective function during fine-tuning, but then claim it doesn't help much in comparison to just training and unsupervised LM.
- I.e. the loss function is a weighted sum of the downstream task loss and the language model loss.
The LM is trained on prose work (actual books), which help it to learn long-range dependencies, causality, etc.
They say the learning rate is increased linearly from zero until it reaches a maximum, then decreases to zero. This is similar to the slanted triangular learning rate in ULMFit
MY 2¢
The main difference between this article and ULMFit seems to be the fact that it uses Transformer architecture rather than a BiLSTM like ULMFit and that ULMFit apparently only applied this to text classification while GPT is applied to a wider set of downstream tasks.
Very interesting how the authors describe the structuring of the fine-tuning architecture depending on the downstream task at hand.
- For example: to adapt the pretrained model to the Textual Entailment task, they concatenate the hypothesis and the possible conclusion and apply the whole thing together (against a 0-1 target I suppose). See below:
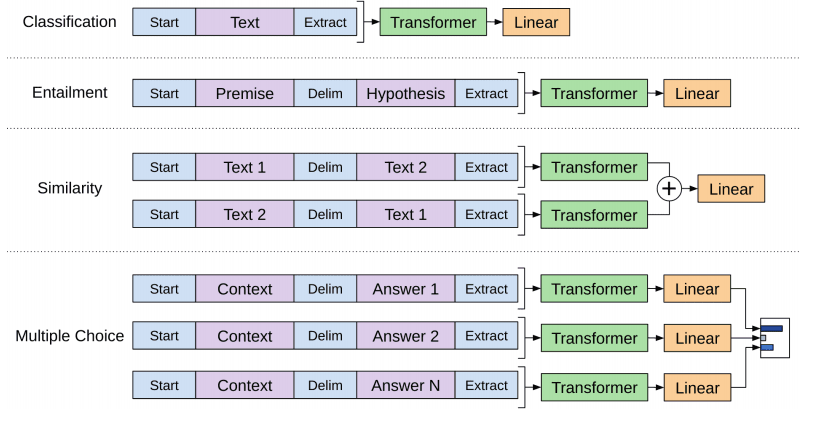 For the supervised task fine-tuning, (step 2 of the strategy),
For the supervised task fine-tuning, (step 2 of the strategy), the architecture is adapted depending on the downstream task at hand.
Source: Radford et al., 2018: Improving Language Understanding by Generative Pre-Training