Paper Summary: Learning to summarize from human feedback
Last updated:Please note This post is mainly intended for my personal use. It is not peer-reviewed work and should not be taken as such.
 Learning to summarize from human feedback Source
Learning to summarize from human feedback Source
WHAT
RLHF1 is applied to the task of generating abstractive summaries of an input text.
WHY
The authors wanted to extend the work by Ziegler et al 2019, using offline instead of online RL and better managing the labelers.
HOW
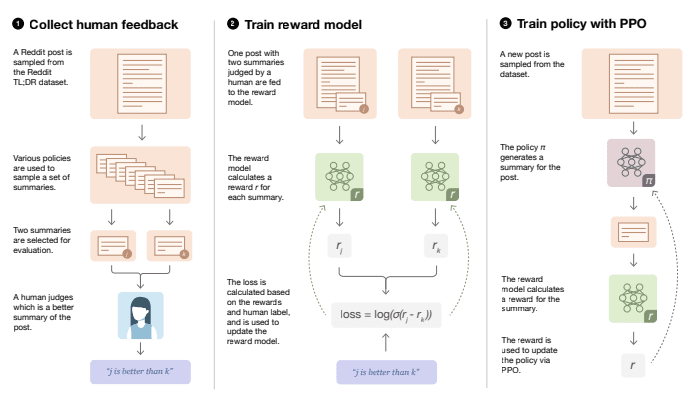
1) Generate and/or collect pairs of summaries and have a human labeler select the best of the two.
2) Train a Reward model to be able to tell which of a pair of summaries was the best one.
-
3) Use the Reward model from Step 2 to train an RL model using PPO.
- I.e.: generate a summary for a post then get its score from the reward model, update the RL model, and repeat.
 The RL flow used by Stiennon et al. Remarkably similar to the image from the InstructGPT Paper.
The RL flow used by Stiennon et al. Remarkably similar to the image from the InstructGPT Paper. Source
CLAIMS
- Abstractive summarization with RLHF works much better than previous baselines from SFT only.
- Both in terms of subjective quality and ability to generalize to unseen domains.
QUOTES
On generalization: "Our human feedback models can also generate excellent summaries of CNN/DM news articles without any further training."
On using numeric metrics to measure subjective quality: "We also find that ROUGE fails to track sample quality as our models improve."
EXTENDS/USES
The setup is adapted from Ziegler et al 2019.
Model architecture is based on GPT-3, using 1.7 and 6.7B parameters.
RLHF (Christiano et al., 2017)
TL;DR summarization dataset from Reddit.
NOTES
The RL setup is offline, not online as in the previous paper by Ziegler et al.
The initial generation of summaries is done with a simple LLM, and it's fully in-context.
~The KL-divergence correction in the reward function to prevent the RL model from finding hacks seems to have been introduced here.~ Actually, it was used at least as far back as in the TRPO article, which preceded PPO.
MY 2¢
Interesting points about the length vs quality tradeoff. Models that generate longer summaries may be taken to be better but they are kind of cheating.
The authors say that generating the summaries was done in a zero-shot manner but they then say that they provided examples in the context, which makes it few-shot (not zero-shot)
 .
.The authors correctly predict several problems related to hallucinations and possible bias generated by using humans to direct model preferences.
1: The acronym RLHF is nowhere to be found in this article, however.