Paper Summary: Text Summarization Techniques: A Brief Survey
Last updated:Please note This post is mainly intended for my personal use. It is not peer-reviewed work and should not be taken as such.
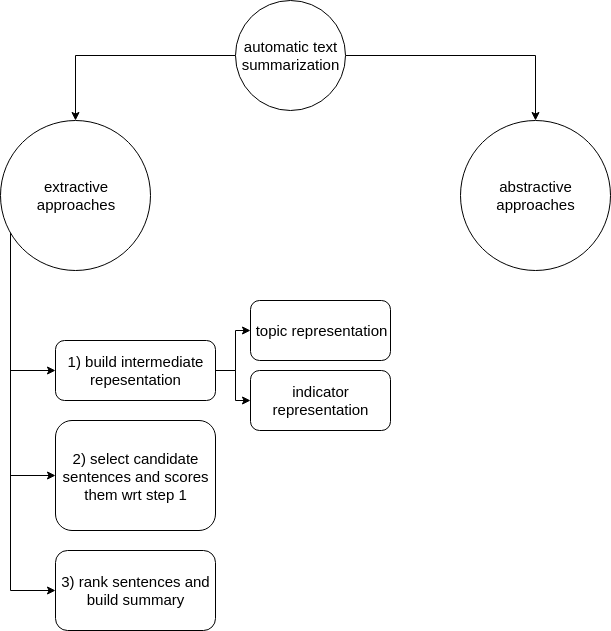 Overview of automatic text
Overview of automatic text summarization strategies.
This article focuses on extractive approaches only.
WHAT
Surveys extractive text summarization techniques.
CLAIMS
There are two distinct approaches to automatic text summarization: extractive and abstractive approaches.
Extractive approaches: Approaches that identify important sections/sentences/phrases and select them.
Abstractive approaches: Actually parses the text semantically and tries to generate a passing summarization that may or may not include actual sentences from the original text. A much harder problem, more similar to what humans actually do.
All extractive summarization approaches perform the following three tasks:
1) Construct an intermediate represention of the text
2) Scores candidate sentences/phrases based upon the representation found on step 1)
3) Builds a summary containing a desired number of sentences (probably ranked by score).
QUOTES
- "Even though summaries created by humans are usually not extractive, most of the summarization research today has focused on extractive summarization"
ROUGE
ROUGE is a metric used to compare two blocks of text. It can be used to evaluate automatically generated summaries with respect to ground truth (original summaries, titles, etc).
$$ \text{ROUGE}_n=\frac{p}{q} $$
Where \(p\) is the number of common \(n\)-grams occurring both in the generated and in the original summary, and \(q\) is the number of \(n\)-grams in the original summary.
NOTES
- The earliest article on automatic text summarization seems to be 1958 with Luhn: "The automatic creation of literature abstracts"