Paper Summary: Fine-tuned Language models are Zero-Shot Learners
Last updated:Please note This post is mainly intended for my personal use. It is not peer-reviewed work and should not be taken as such.
 Finetuned Language models are Zero-Shot Learners Source
Finetuned Language models are Zero-Shot Learners Source
WHAT
Fine-tune LaMDA-PT 137B with NLP tasks framed as natural language instructions. The final model is called FLAN.
WHY
To understand the impact of instruction-tuning LMs for free-form NLP problems.
HOW
Took supervised datasets for 12 NLP tasks and rewrote those as pure natural language tasks.
Fine-tuned a LaMDA-PT 137B model on the rewritten tasks
Compared the results from the fine-tuned model (FLAN) with the pre-trained version (LaMDA-PT) and GPT-3 on several regimes1 and tasks.
CLAIMS
FLAN (zero-shot) beats GPT-3 (few-shot) FLAN performs better using zero-shot in some tasks than GPT-3 using few-shot examples.
Instruction-tuning enhances results even on unseen tasks
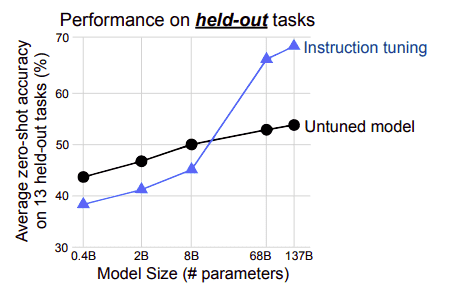 Fine-tuning only helps once the pre-trained
Fine-tuning only helps once the pre-trained model reach a minimum number of parameters. Under that threshold, fine-tuning
actually hurts performance. Source
EXTENDS/USES
LaMDA-PT 137B
Data processing from T5, by Raffel et al.2019. (summary)
Prompt Tuning, by Lester et al., 2021
MY 2¢
- This is T5 on steroids. Similar setup with a much larger scope.
References
1: Zero-shot and few-shot learning.