Spark SQL Date/Datetime Function Examples
Last updated:
- to_date example
- to_date, custom date format
- to_timestamp example
- to_timestamp, custom datetime format
- timestamp to date
- date to timestamp at zero hours
- Format timestamp
- Format date
- Get hour from timestamp
- Current timestamp
- Current date
- Start of the week
Spark version 2.4.8 used
All code available on this jupyter notebook
Examples on how to use common date/datetime-related function on Spark SQL
For stuff related to date arithmetic, see Spark SQL date/time Arithmetic examples: Adding, Subtracting, etc
to_date example
Use to_date(Column) from org.apache.spark.sql.functions.
import org.apache.spark.sql.functions.to_date
// source dataframe
val df = Seq(
("notebook","2019-01-01"),
("notebook", "2019-01-10"),
("small_phone", "2019-01-15"),
("small_phone", "2019-01-30")
).toDF("device", "purchase_date").sort("device","purchase_date")
// column "purchase_date" is of type string
df.dtypes
// >>> Array((device,StringType), (purchase_date,StringType))
// call to_date passing the date string column
val df2 = df.withColumn("purchase_date",to_date($"purchase_date"))
df2.dtypes
// >>> Array((device,StringType), (purchase_date,DateType))
to_date, custom date format
Pass a format string compatible with Java SimpleDateFormat
import org.apache.spark.sql.functions.to_date
val df = Seq(
("notebook","27/12/2019"),
("notebook", "01/12/2019"),
("small_phone", "23/01/2019"),
("small_phone", "27/12/2019")
).toDF("device", "purchase_date").sort("device","purchase_date")
// parse string into Date
df.withColumn("purchase_date",to_date($"purchase_date", "dd/MM/yyyy"))
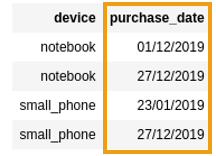 BEFORE: column of type
BEFORE: column of type String with dates in custom format
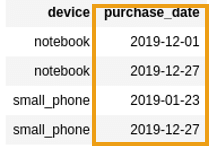 AFTER: column parsed to type
AFTER: column parsed to type Date
to_timestamp example
Use to_timestamp(StringColumn).
import org.apache.spark.sql.functions.to_timestamp
// source dataframe
val df = Seq(
("notebook","2019-01-01 00:00:00"),
("notebook", "2019-01-10 13:00:00"),
("small_phone", "2019-01-15 12:00:00"),
("small_phone", "2019-01-30 09:30:00")
).toDF("device", "purchase_time").sort("device","purchase_time")
// column "purchase_time" is of type string
df.dtypes
// >>> Array((device,StringType), (purchase_time,StringType))
// call to_date passing the datetime string column
val df2 = df.withColumn("purchase_time",to_timestamp($"purchase_time"))
df2.dtypes
// >>> Array((device,StringType), (purchase_time,TimestampType))
to_timestamp, custom datetime format
Pass a format string compatible with Java SimpleDateFormat
Otherwise, it will result in null values.
import org.apache.spark.sql.functions.to_timestamp
val df = Seq(
("notebook","27/12/2019 12:00"),
("notebook", "01/12/2019 00:00"),
("small_phone", "23/01/2019 12:00"),
("small_phone", "27/12/2019 12:00")
).toDF("device", "purchase_time").sort("device","purchase_time")
// providing the format like this prevents null values
df.withColumn("purchase_time",to_timestamp($"purchase_time","d/M/y H:m"))
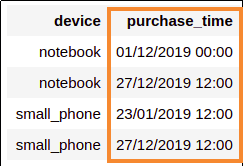 Source dataframe with string columns
Source dataframe with string columns
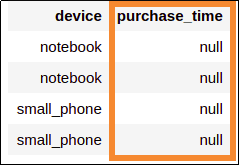 Calling to_timestamp without a
Calling to_timestamp without a custom format gave you
null values in this case
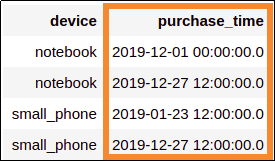 Correctly parsed values when
Correctly parsed values when you provide a custom format
timestamp to date
use to_date(TimestampColumn)
import java.sql.Timestamp
import org.apache.spark.sql.functions.to_date
val df = Seq(
("notebook",Timestamp.valueOf("2019-01-29 12:00:00")),
("notebook", Timestamp.valueOf("2019-01-01 00:00:00")),
("small_phone", Timestamp.valueOf("2019-01-15 23:00:00")),
("small_phone", Timestamp.valueOf("2019-01-01 09:00:00"))
).toDF("device", "purchase_time").sort("device","purchase_time")
// call to_date as you would on a string column
df.withColumn("purchase_date",to_date($"purchase_time"))
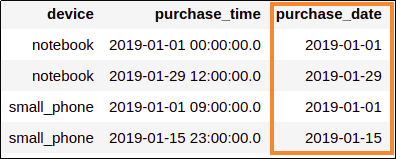 Derived column
Derived column purchase_date was created by calling to_date on a
Timestamp column, namely purchase_time
date to timestamp at zero hours
Use to_timestamp(DateColumn) to convert a date to a timestamp with the same date, at midnight.
import java.sql.Date
import org.apache.spark.sql.functions.to_timestamp
val df = Seq(
("notebook",Date.valueOf("2019-01-29")),
("notebook", Date.valueOf("2019-01-01")),
("small_phone", Date.valueOf("2019-01-15")),
("small_phone", Date.valueOf("2019-01-01"))
).toDF("device", "purchase_date").sort("device","purchase_date")
df.withColumn("purchase_time",to_timestamp($"purchase_date"))
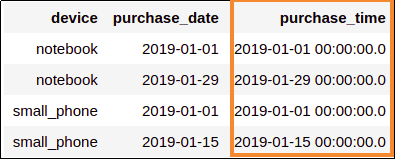 Added a new column
Added a new column purchase_time by calling to_timestamp on existing column
purchase_date
Format timestamp
See Java SimpleDateFormat for ways to define the format
Use date_format(Column, formatStr) to apply custom formatting to both Timestamp and Date columns to String:
import java.sql.Timestamp
import org.apache.spark.sql.functions.date_format
val df = Seq(
("notebook",Timestamp.valueOf("2019-01-29 12:00:00")),
("notebook", Timestamp.valueOf("2019-01-01 00:00:00")),
("small_phone", Timestamp.valueOf("2019-01-15 23:00:00")),
("small_phone", Timestamp.valueOf("2019-01-01 09:00:00"))
).toDF("device", "purchase_time").sort("device","purchase_time")
df.withColumn("formatted_purchase_time",date_format($"purchase_time","y-MM"))
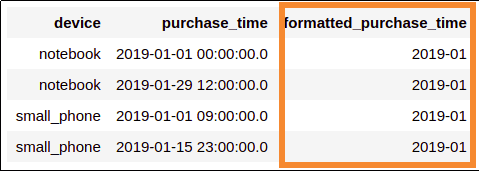 Created a new column by using
Created a new column by using "y-MM" format
Format date
custom timestamp formatting can be used for applying custom formatting to Date columns too.
Get hour from timestamp
There is a method called hour (also others such as minute, second, etc)
import org.apache.spark.sql.functions.hour
val df = Seq(
("foo", "2019-01-01 01:00:00.000"),
("bar", "2019-01-01 12:30:00.000"),
("baz", "2019-01-01 23:01:00.000")
).toDF("col1", "some_timestamp")
df.withColumn("hour", hour($"some_timestamp"))
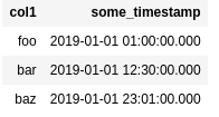 Dataframe with a timestamp column
Dataframe with a timestamp column
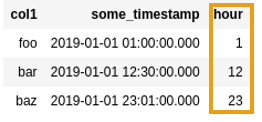 After extracting the hour from
After extracting the hour from the timestamp
Current timestamp
Use current_timestamp
import org.apache.spark.sql.functions.current_timestamp
val df = Seq(
("foo"),
("bar"),
("baz")
).toDF("col1")
df
.withColumn("now", current_timestamp)
 Create a column with the current timestamp, down to
Create a column with the current timestamp, down tothe milliseconds
Current date
Use current_date to get today's date:
import org.apache.spark.sql.functions.current_date
val df = Seq(
("foo"),
("bar"),
("baz")
).toDF("col1")
df
.withColumn("today", current_date)
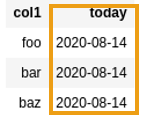 Use the aptly named
Use the aptly named current_date to get today's date.
Start of the week
It's often useful to group data by the week in which it occurred (and then do group-bys and other aggregations).
To get the beginning of the week, use this helper function (dayNameToIndex) together with date_format:
import org.apache.spark.sql.{Column, DataFrame}
import org.apache.spark.sql.functions._
// dummy dataframe for testing
val df = Seq(
("2018-12-28"),
("2019-01-01"),
("2019-01-04")
).toDF("source_date")
// turn a day name (like "Wed") to its position on the week (e.g. 3)
def dayNameToIndex(col: Column) : Column = {
when(col.isNull, null)
.when(col === "Sun", 0)
.when(col === "Mon", 1)
.when(col === "Tue", 2)
.when(col === "Wed", 3)
.when(col === "Thu", 4)
.when(col === "Fri", 5)
.when(col === "Sat", 6)
}
// need to use expr because the number of days to subtract is a column value
df
.withColumn("day_index", dayNameToIndex(date_format(col("source_date"), "E")))
.withColumn("week_start", expr("date_sub(source_date, day_index)"))
.drop("day_index") // dont need this
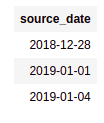 BEFORE: a column with a date
BEFORE: a column with a date
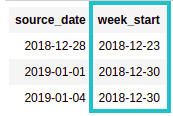 AFTER: new column with the
AFTER: new column with the start of the week of
source_date